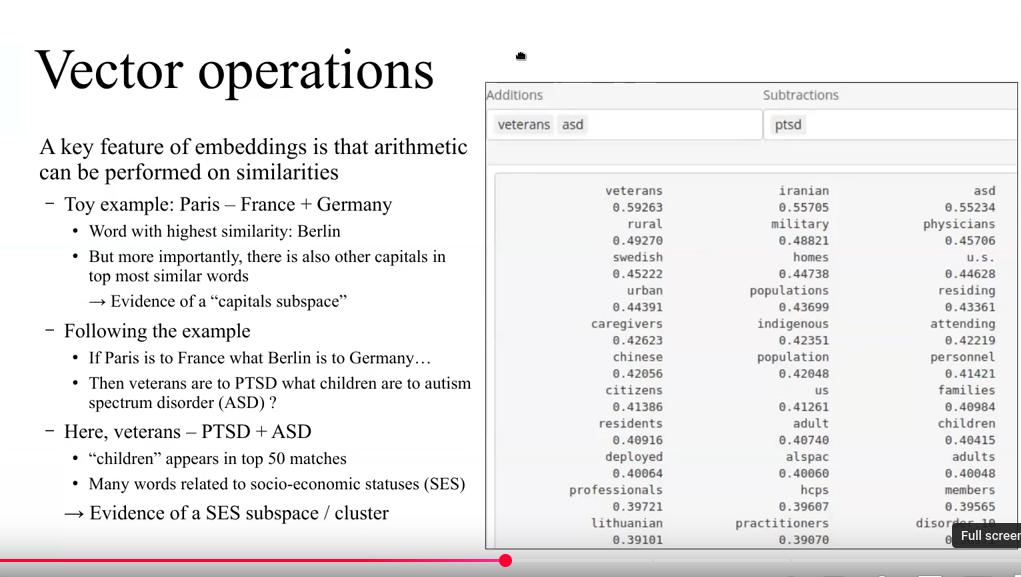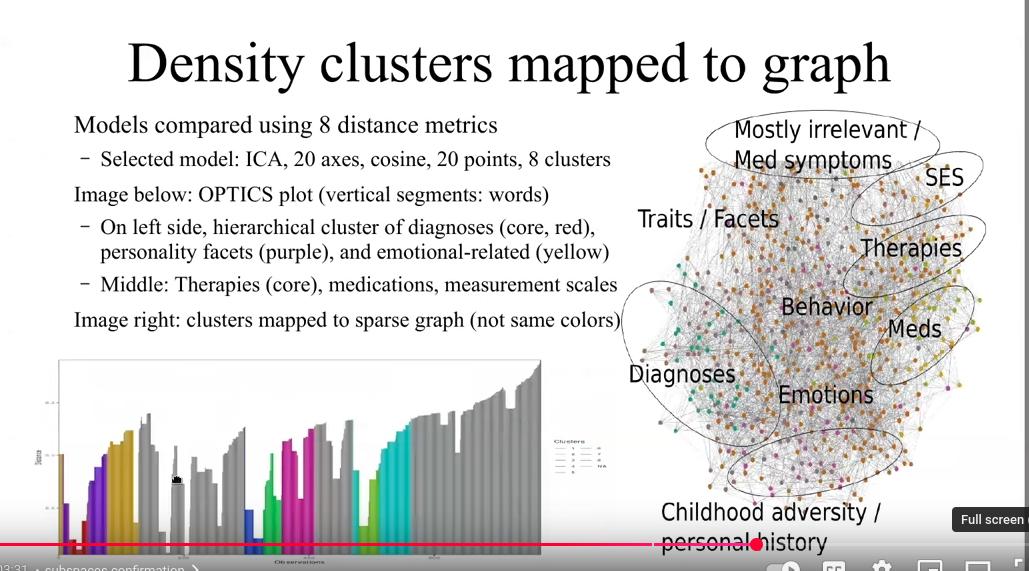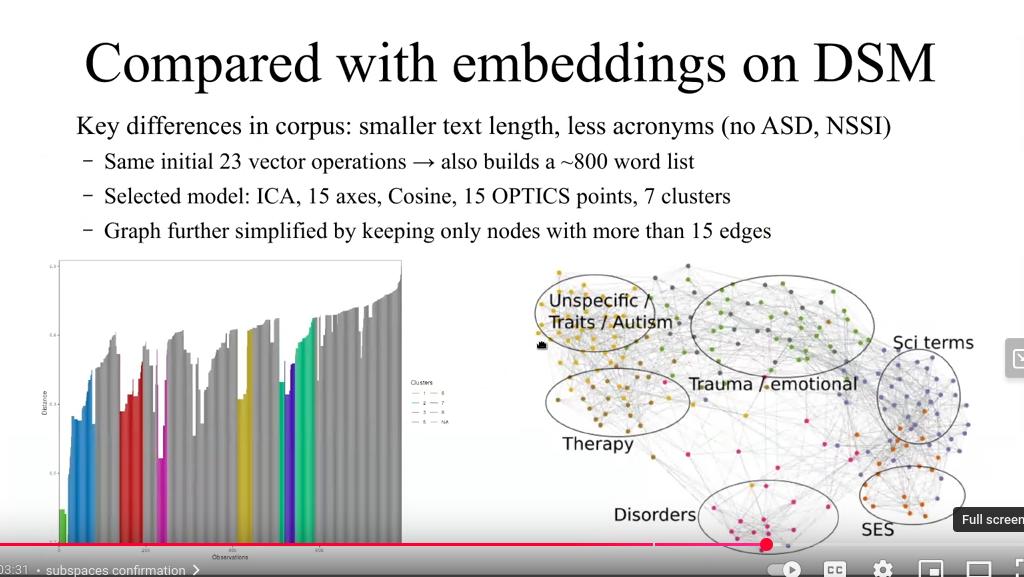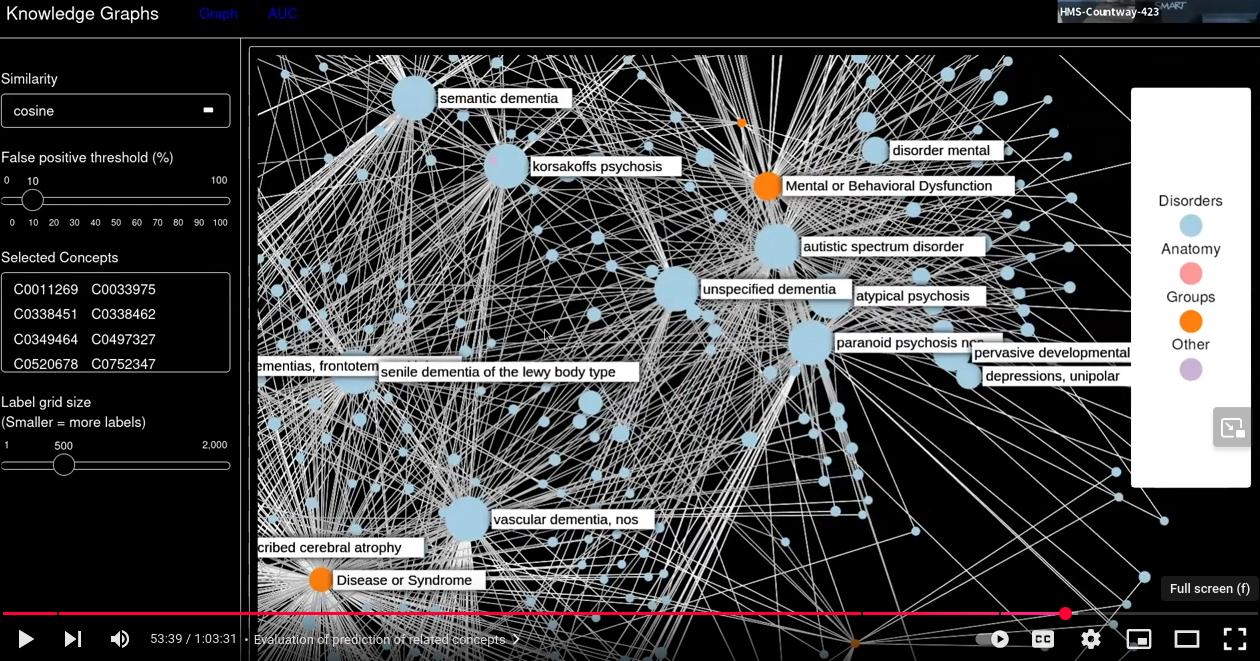
This suicide prevention workshop, developed with Veterans Affairs, aims to assist clinicians by analyzing health data to improve follow-up with at-risk patients, enable access to relevant notes, and share insights while preserving confidentiality. It covers the project overview, the Diagnostic Manual’s role, a proposed diagnosis, an analysis of suicide publications, and instructions for reproducing the work - all to leverage data and expertise for suicide prevention, especially for military and veterans.