This suicide prevention workshop, developed with Veterans Affairs, aims to assist clinicians by analyzing health data to improve follow-up with at-risk patients, enable access to relevant notes, and share insights while preserving confidentiality. It covers the project overview, the Diagnostic Manual’s role, a proposed diagnosis, an analysis of suicide publications, and instructions for reproducing the work - all to leverage data and expertise for suicide prevention, especially for military and veterans.
00:00 Introduction and problematization
02:46 Preliminary exploration
43:29 Subspaces confirmation
50:24 Evaluation of prediction of related concepts
Mental health related diagnoses have been on the rise these last years, especially since the pandemic. In the CELEHS laboratory, we analyze electronic health records to help clinicians identify at-risk patients requiring follow-up.
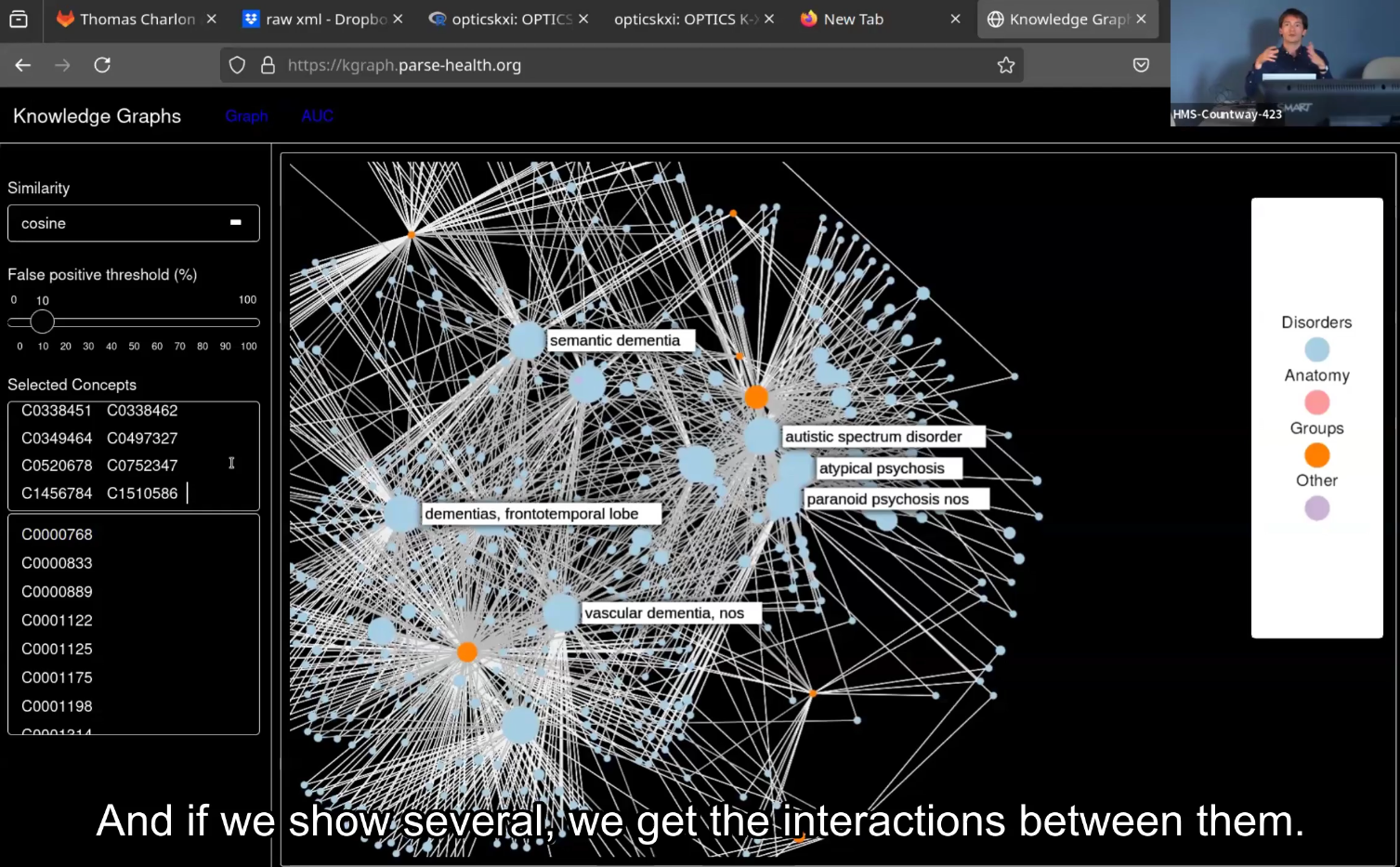
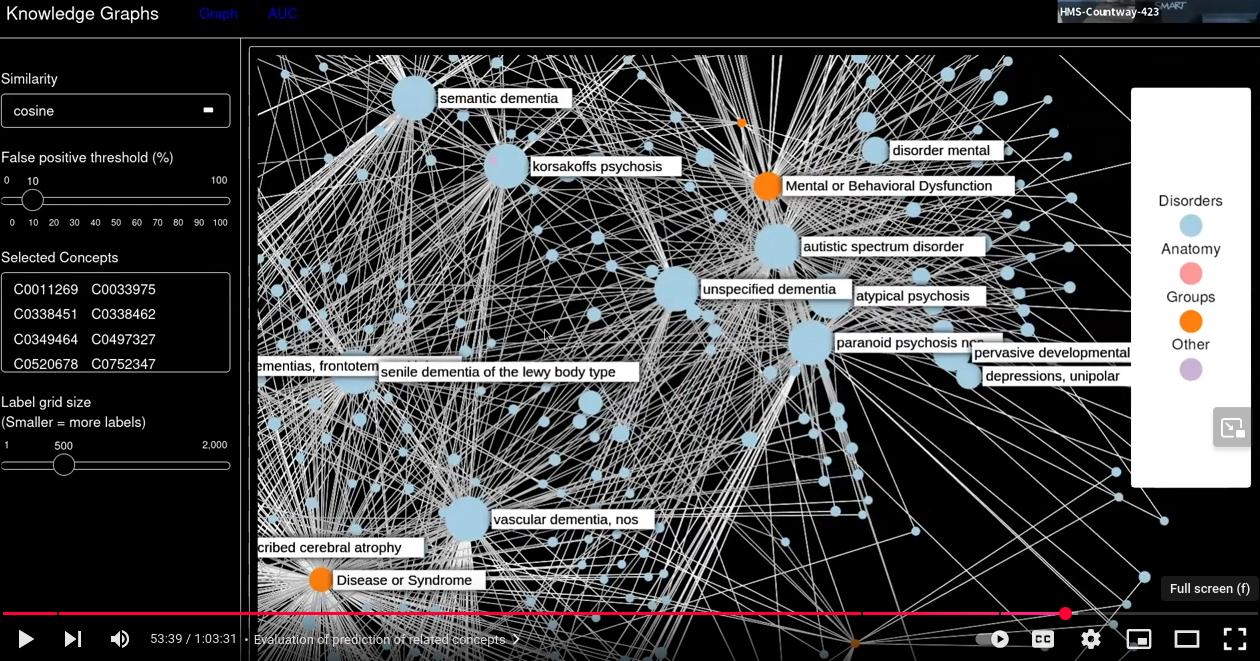
In this talk I will present the results of Glove word embeddings on 8,000 open-access suicide-related publications, using the text2vec, opticskxi and sigmagraph R packages. I developed a novel methodology based on random projections to efficiently find diverse clusters of related concepts in unstructured text data, and evaluate the results by predicting pairs of related concepts, and comparing them to clinician-based known relationships. While many biomedical natural language processing approaches focus on the analysis of specific known concepts, as the ones indexed by the Unified Medical Language System (UMLS), the analysis of the complete text can enable to find novel relationships and borderline concepts.
The Diagnostic and Statistical Manual of Mental Disorders (DSM) is the main reference for clinicians to diagnose mental health diseases, and describes sets of symptoms that form the required diagnostic criteria for each disease. The DSM emphasizes that many patients are diagnosed with multiple conditions, and that current diagnoses could benefit from introducing multidimensional assessments, by taking into account the severity, intensity, duration, and combinations of symptoms, to form more precise diagnostics and help treatment. The DSM also underlines the necessity for diagnoses that take into account the spectrum and gradients of disorders observed, as in schizoaffective and autism spectrum disorders. To this end, the analysis of unstructured text data can help identify clusters of conditions and enable new multidimensional classifications of mental health disorders.
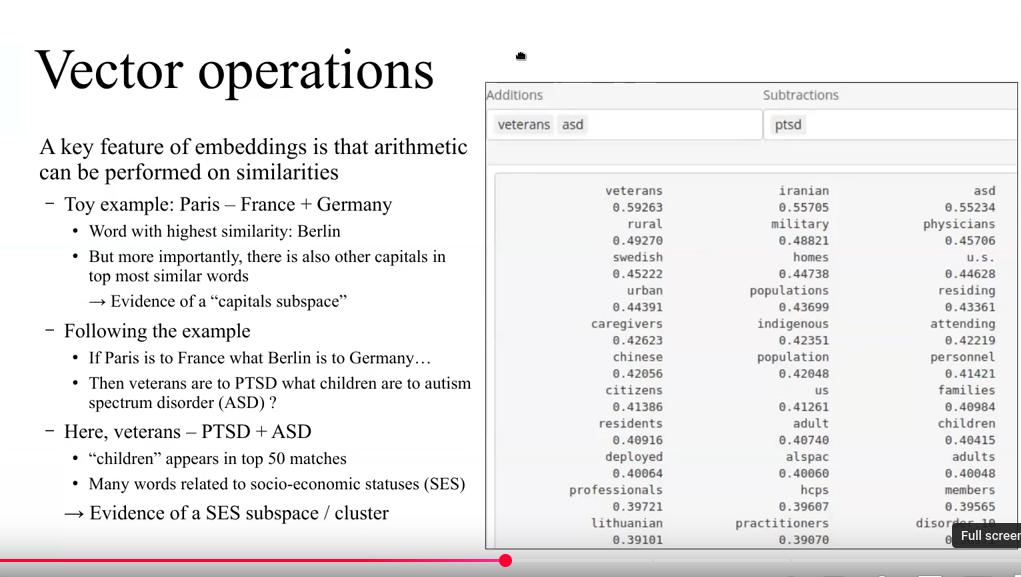
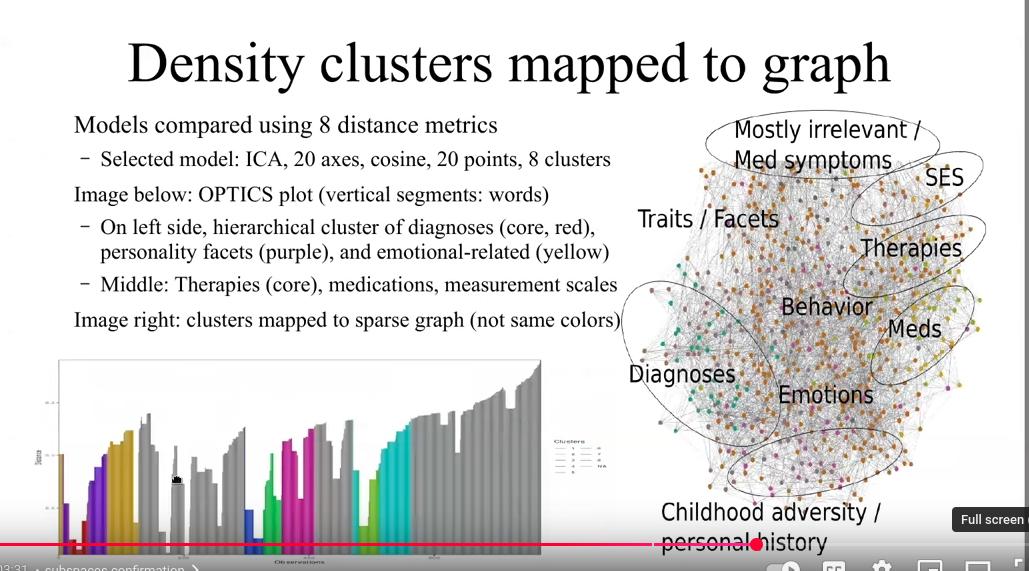
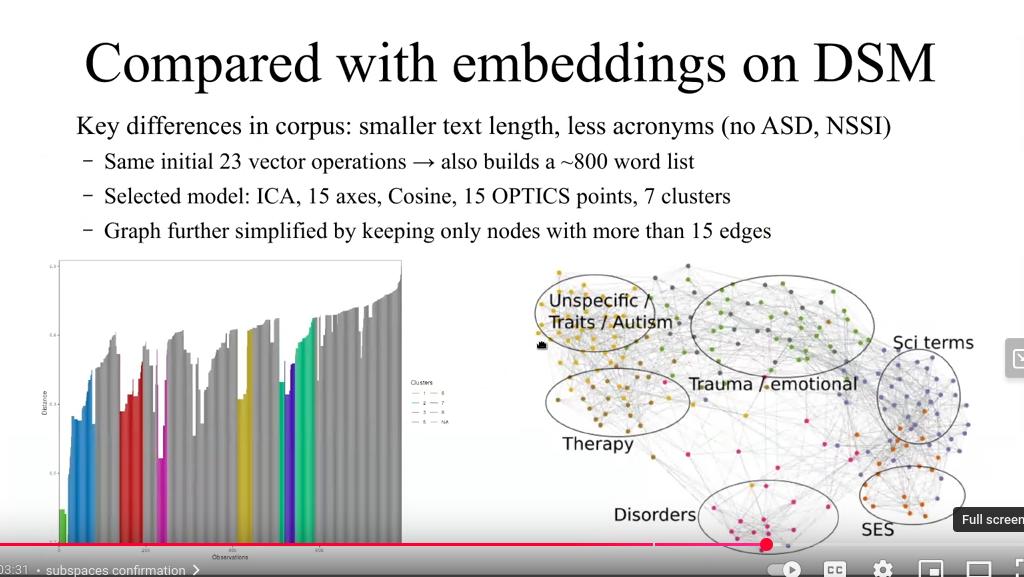
My talk will first present an overview of the problematic as underlined in the DSM and introduce Glove word embeddings using the text2vec package on a set of 8,000 open-access suicide-related publications. I then demonstrate how to explore the embeddings using vector operations to manually find clusters of related concepts, and in a second step automate the discovery of such clusters using the density-based clustering package opticskxi, and visualize the clusters as graphs using the sigmagraph network visualization package. Further clusters are then discovered by applying semi-directed vector operations, a novel method inspired by random projections. In a last step, I introduce ways to evaluate such clusters, using a database of 17,000 known concepts pairs curated by clinicians with expert knowledge, by predicting pairs of related concepts using a false positive threshold cut-off on cosine similarities.
Novel methodologies in natural language processing will enable us to further understand mental health disorders and their interactions. Specific disorders have been associated to personality traits, as schizophrenia with neuroticism and autism with obsessive-compulsive, and the modeling of such interactions and the further discovery of novel interactions will enable us to enhance the treatment of mental health disorders and identify clinically-actionable features.
Links
© All rights reserved, Thomas Charlon, 2025.
Template by Bootstrapious. Ported to Hugo by DevCows.