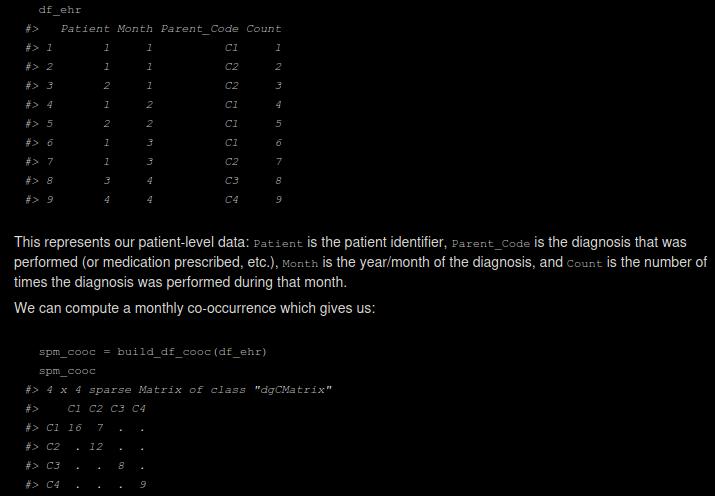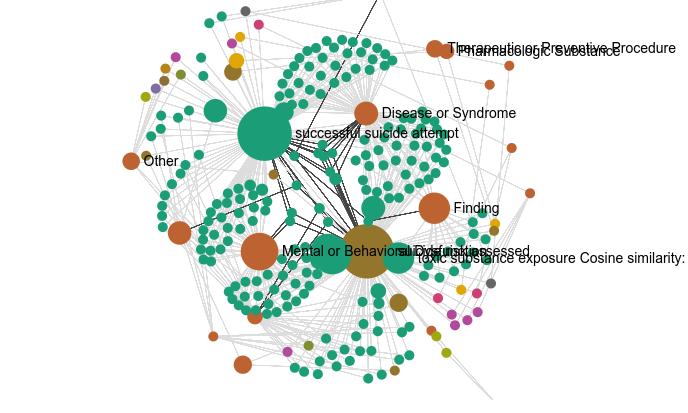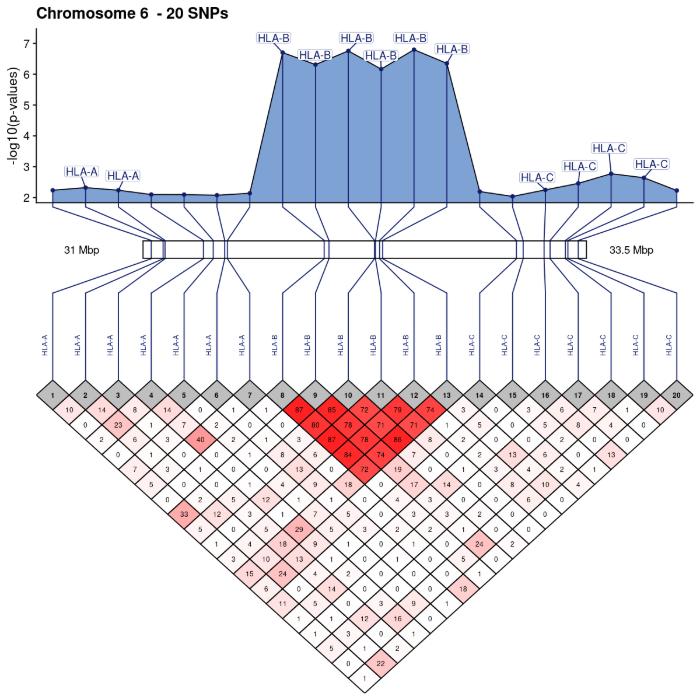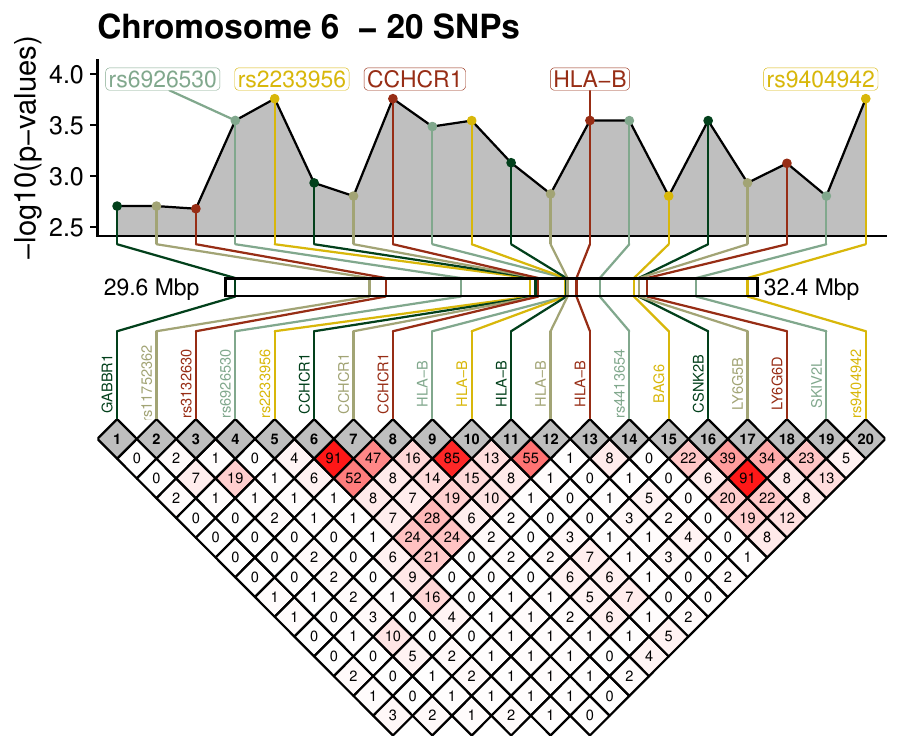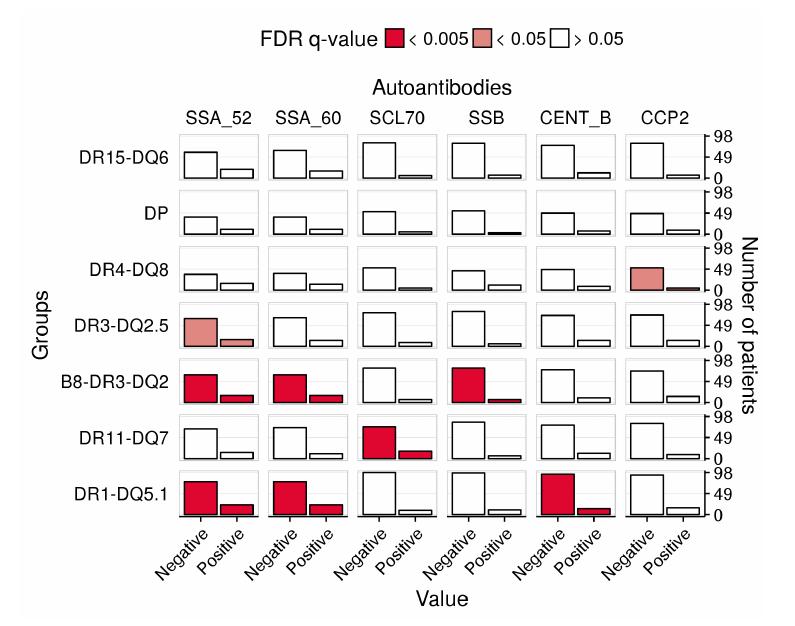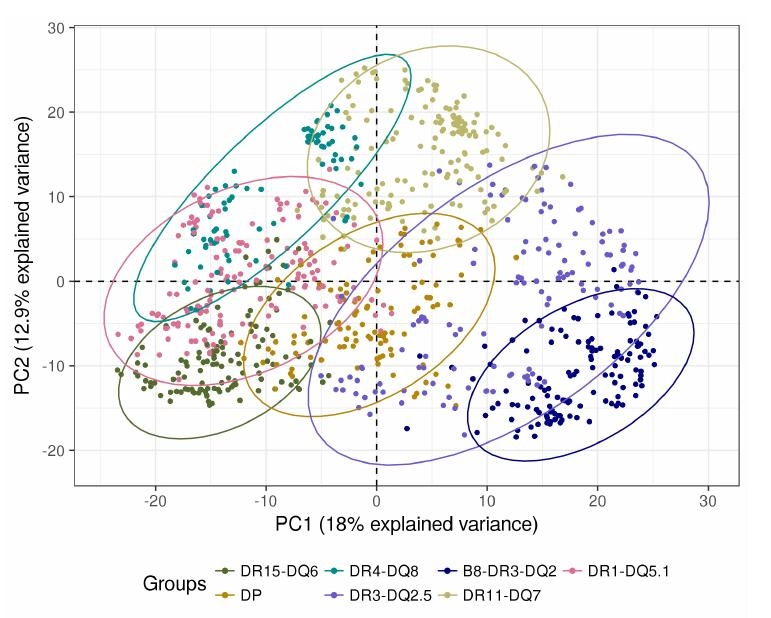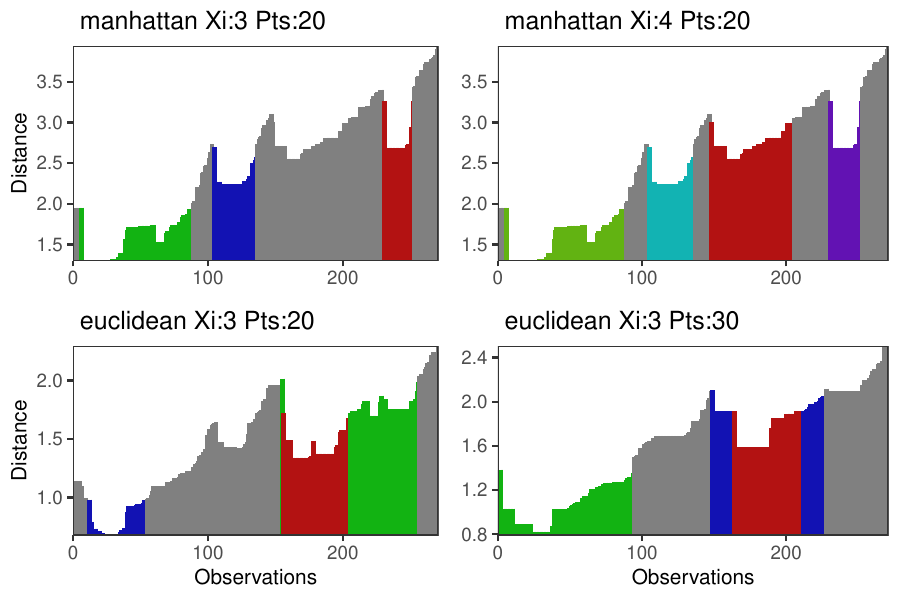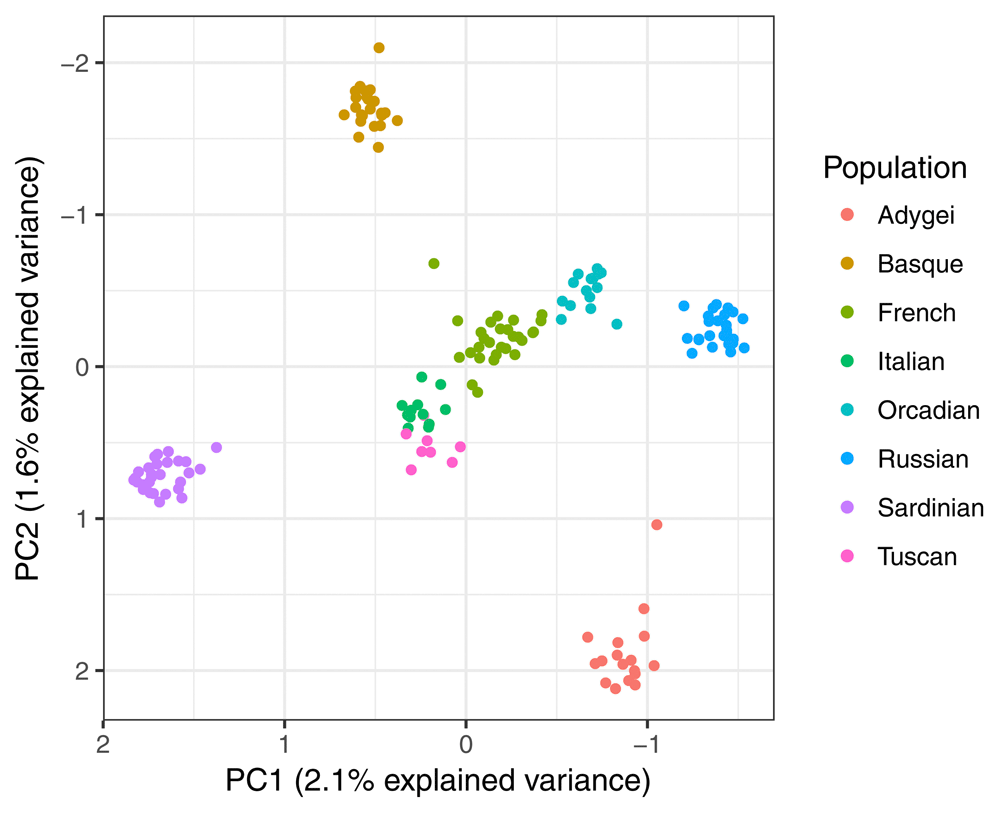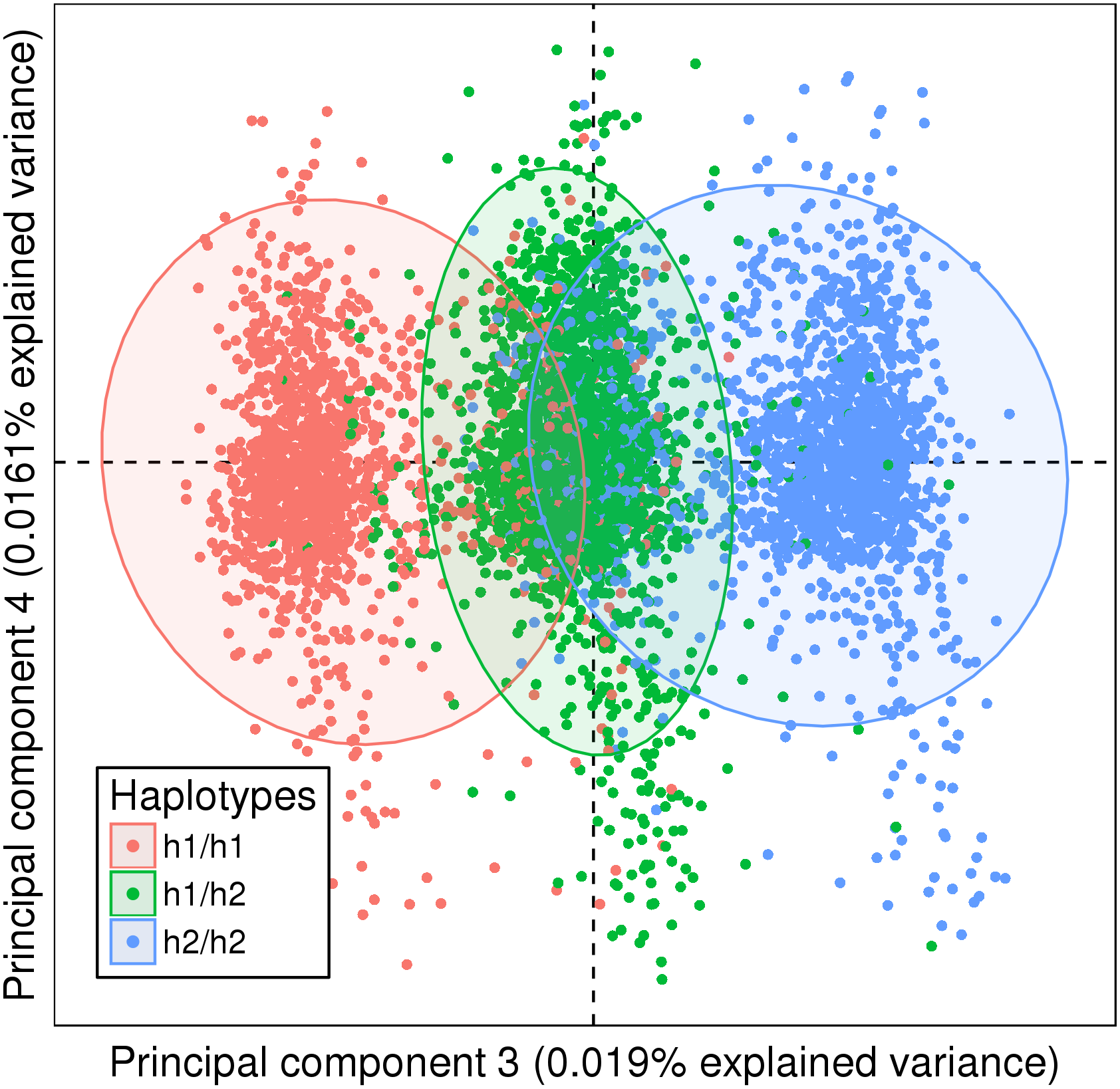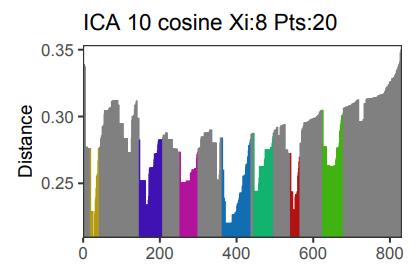
The OPTICS k-Xi density-based clustering pipeline now integrates ensemble metrics which enable to increase the stability of the clusters and the reproducibility of the results on evaluation datasets. Up to now, OPTICS k-Xi computed several distance-based metrics but did not implement any way of merging together their results, it was up to the user to select the most relevant metric or to merge them together. Recently, we applied the pipeline on natural language processing embeddings and the choice of the relevant metric revealed complex and the clusters were unstable. To alleviate this, we implemented ensemble metrics and models in the OPTICS k-Xi pipeline. Three other improvements have also been implemented: the selection of the cosine distance; a parameter to set a maximum cluster size; and a parameter to select a minimum number of clusters. This vignette showcases and introduce the new developments of the opticskxi package, with a particular focus on ensemble metrics and models.